The BYOK Architecture: Securing User-Managed AI Keys with AES-256-GCM

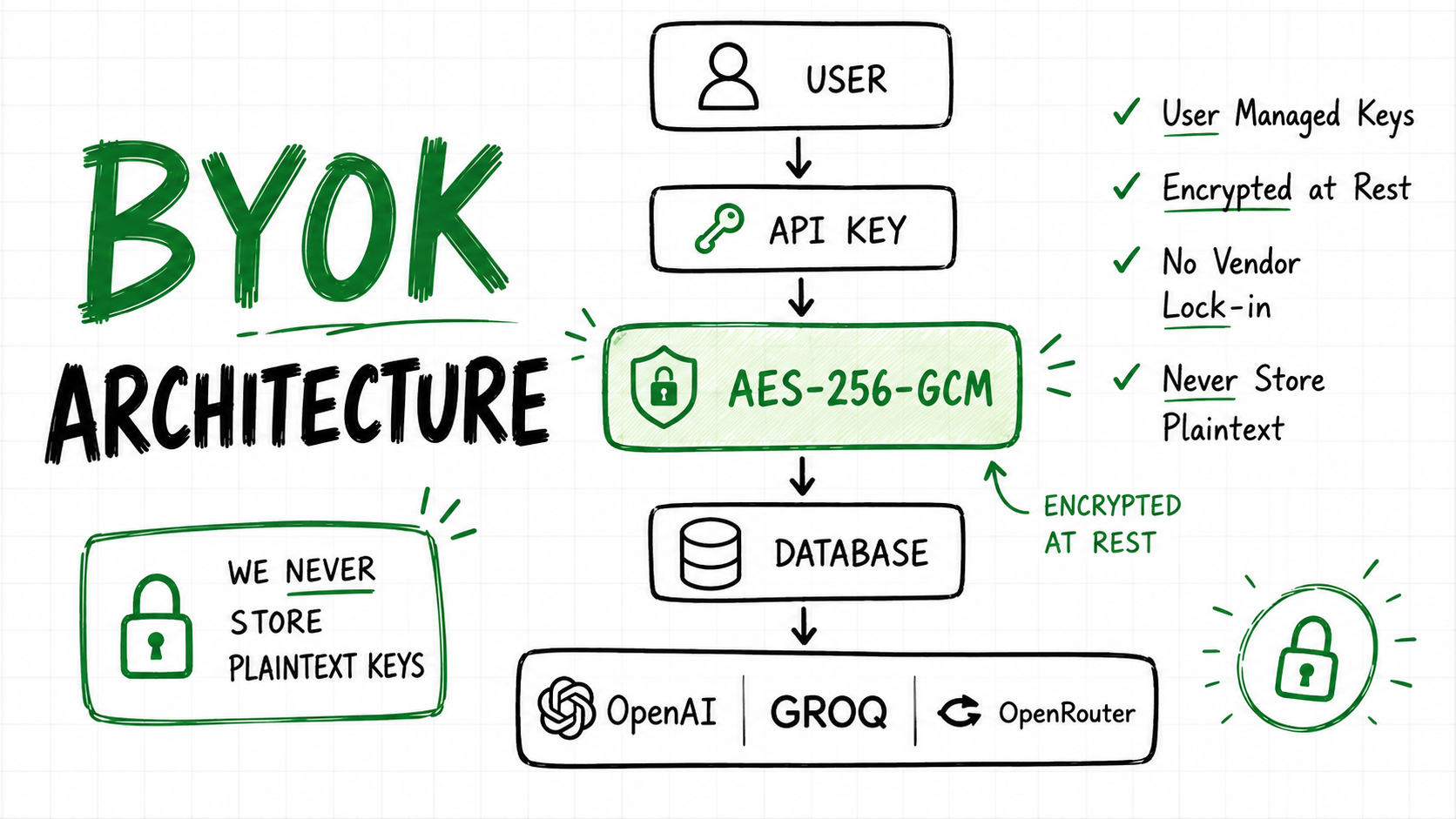
Most AI platforms hardcode their API keys and charge your per query. We let users bring their own keys, encrypt them with AES-256-GCM, and never see the plaintext.
It's called BYOK (Bring Your Own Key). And it's the architectural decision that makes Labas fundamentally different from every other AI exam platfrom.
Key Takeaways
The BYOK Decision: Why We Don't Hardcode API Keys
In 2026, the AI wrapper space is crowded. Most follow the same pattern: the platform owns the API keys, users pay per query (or subscribe monthly), and the platform absorbs the AI cost. It's a classic SaaS model but it has three problems:
We chose the opposite: users bring their own keys. They pay their AI provider directly. We never see their keys in plaintext. The platform is free to self-host.
This decision shaped every layer of our architecture from the database schema to the HTPP client to the encryption module.
The Encryption Module: 59 Lines of Production-Grade Security
The encryption module (packages/api/src/lib/encryption.ts) is 59 lines. It does one thing: encrypt and decrypt API keys using AES-256-GCM.
Why AES-256-GCM, Not AES-256-CBC?
AES-256-CBC is the "default" encryption algorithm in many tutorials. But CBC has a critical weakness: it doesn't authenticate the ciphertext. An attacker can modify the encrypted data, and the decryption will succeed producing garbled output that might be exploitable.
AES-256-GCM (Galois/Counter Mode) includes an authentication tag. If the ciphertext is modified, decryption fails. This is called authenticated encryption and it's the NIST-recommended approach for new applications.
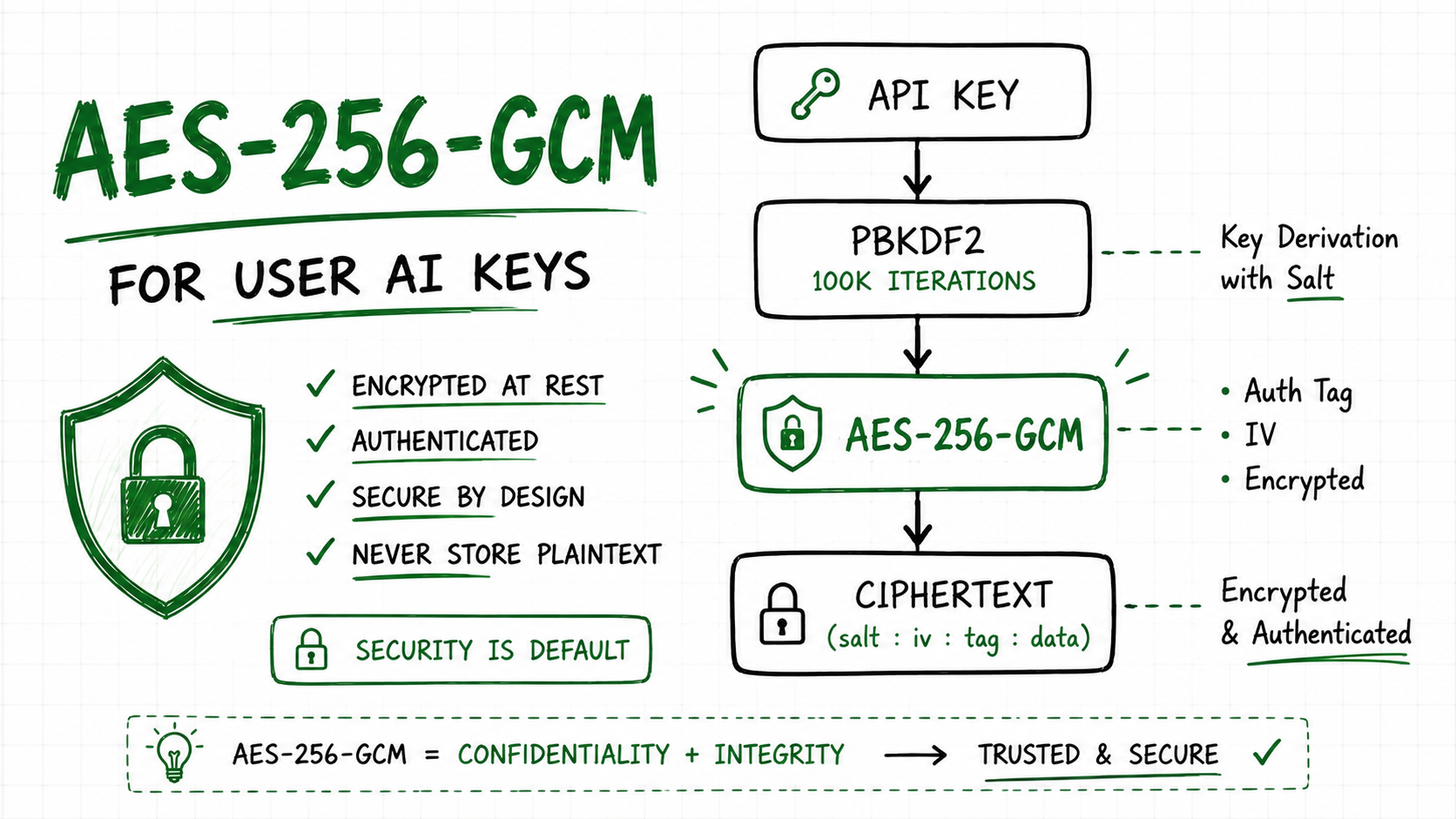
Why PBKDF2 with 100000 Iterations?
The encryption key ( API_KEY_ENCRYPTION_KEY ) is a server-side secret. But we still derive the actual encryption key using PBKDF2 with a random salt and 100000 iterations. Why?
The Encrypted Format
The output format is salt:iv:authTag:ciphertext all base64-encoded, colon-separated:
Each component servers a purpose:
Decryption parses theses four parts, derives the key, and verifies the auth tag before returning the plaintext:
The setAuthTag call is critical without it, GCM mode doesn't authenticate the ciphertext.
The API Client: SSRF Protection for User-Managed Keys
When users bring their own keys, they can point to any OpenAI-compatible endpoint including http://localhost:11434 for local Ollama models. This flexibility is powerful, but it introduces a security risk: SSRF (Server-Side Request Forgery).
A malicious user could set their base_url to http://169.254.169.254/latest/meta-data/ (AWS metadata endpoint) and read cloud credentials through the AI client.
Our client (packages/ai/src/client.ts) blocks this:
The key design choice: localhost is allowed, but private network IPs are blocked in production. This lets developers test with local Ollama models during development, but prevents SSRF attacks when the app is deployed to a cloud environment.
The check runs before every HTTP request:
The Hand-Roll: Why We Didn't Use the OpenAI SDK
Most projects use the official OpenAI SDK. We wrote our own client from scratch. Why?
response_format: { type: "json_object" }. Our client detects this error and retries without parameter:3. Reasoning tag stripping. Reasoning models (DeepSeek, GLM) wrap chain-of-thought in <think> tags. The SDK doesn't strip theses our client does:
4. Truncation retry. If the LLM's JSON responses is cut off mid-stream, the client detects this and retries with higher max_tokens:
5. HTML error page detection. Some API proxies return HTNL error pages instead of JSON. The client detects this and throws a clear error message instead of failing with a cryptic JSON parse error.
Each of theses edge cases was discovered through real usage not from reading documentation. They're the kind of defensive programming that only emerges when you run an AI platform against diverse providers.
The Database Schema: Where Encrypted Keys Live
User API keys are stored in the user_api_key table:
The api_key_encrypted column stores the salt:iv:authTag:ciphertext string. The plaintext is never persisted. When a user initates AI generation, the server:
decryptApiKey().OpenAICompatibleClient with decrypted key.The Businees Model: Why BYOK Makes Sense for Open Source
BYOK isn't just a technical decision it's a business model choice.
with BYOK:
The tradeoff: users need their own AI API key. For students in Indonesia (our target audience), this means getting an OpenAI key, or using a free tier from OpenRouter, or running a local model with Ollama. It's more setup friction but it gives users full control over their AI costs and provider choice.